Delving into the Backlash Against Anthropic: The Clash of Security Dogma, AI Civil War, and Claude's Dilemma Amid US-China Decoupling
Delving into the Backlash Against Anthropic: The Clash of Security Dogma, AI Civil War, and Claude's Dilemma Amid US-China Decoupling
In April 2026, employees at Agricultural Technology Company, a U.S.-based agritech firm, logged into their computers as usual, preparing to use Claude Code for coding, data analysis, and supply chain modeling—only to discover that all 110 employee accounts had been abruptly suspended without prior warning. The company’s network administrator received an email from Anthropic stating: "Suspicious activity detected in violation of usage policies; your account has been suspended."
Although the accounts were collectively banned, backend APIs continued to function normally and billing persisted—so much so that the network administrator even received a payment reminder SMS. Subsequently, the company’s management sent appeal emails and reached out to Anthropic, but to no avail. The suspension of Claude Code brought the entire team to a complete standstill.
At the same time, Chinese internet platforms such as V2EX, Zhihu, and Juejin were flooded with user complaints about Claude: some had just completed Max subscription payments and were instantly banned; others used virtual cards to make successful payments only to be flagged for “account violations”; still others were blocked outright when accessing via third-party tools—four accounts banned within three months, none successfully reinstated after appeals.
In fact, since Anthropic launched its flagship product Claude Code and rose to the top tier of AI models, it has become widely recognized as a notorious account-banning entity.
According to Anthropic’s Transparency Hub report published in January 2026, in just six months during the second half of 2025, the platform had suspended a total of 1.45 million accounts. Among these, 52,000 appeals were filed—but only 1,700 were successful. This translates to an appeal success rate of merely 3.3%.
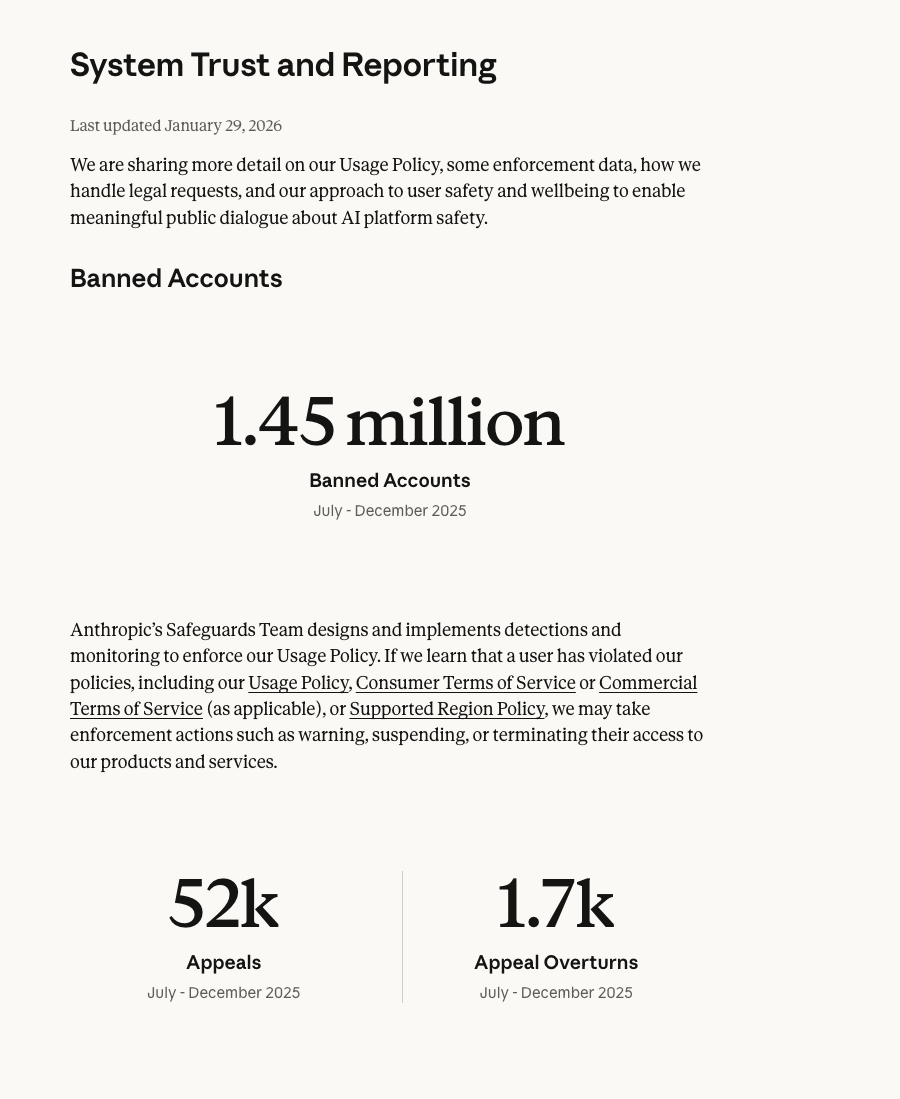
Source: Anthropic
This means that among every 100 users who believe they were wrongfully banned, only about 3 manage to recover their accounts—97 others must simply accept their fate.
Thus, it is clear that Anthropic does not operate under the principle of “investigate first, penalize later.” Instead, its core strategy is preventive enforcement—prioritizing broad interception to squash risks at their inception, adhering to a “better to wrongly ban 1,000 than miss one” philosophy.
In contrast, neighboring platforms like ChatGPT and Google Gemini adopt relatively more lenient approaches.
ChatGPT shows greater tolerance toward third-party tools and edge-case prompts, resulting in looser bans.
Gemini, even when tightening controls occasionally, rarely resorts to surprise mass penalties or indiscriminate purges.
Only Anthropic treats account suspensions as routine—with Claude Code becoming a notorious hotspot for bans.
Why then are Anthropic’s user policies so harsh? The reasons are complex and layered.
Beyond founder Dario Amodei’s personal convictions, this stems from the schism between OpenAI factions, Silicon Valley capital power struggles, the ideological war between the U.S. AI safety and accelerationist camps, and the broader geopolitical chess game of decoupling between China and the U.S. in AI—essentially a hidden battle over control of AI’s future and global technological barriers.
Let us now unpack this layer by layer.
The root cause behind Anthropic’s stringent risk controls lies deep in the life trajectory of its founder, Dario Amodei. Every choice he made, every conviction he held, ultimately became Anthropic’s “zero-tolerance” doctrine—and also the source of countless user suspension emails.

Dario Amodei’s recent official portrait. Source: Fortune
Born in 1983 in San Francisco, Dario Amodei grew up in a modest immigrant family. His father was an Italian-American leather craftsman, known for his stubborn integrity and strong sense of right and wrong.
His mother, of Jewish descent, managed library renovation projects, meticulous in her work and instilled in Dario early on the belief that “responsibility outweighs everything else.”
This upbringing shaped Dario’s rigid, principle-driven personality—one unwilling to compromise or tolerate ambiguity.
Even as a child, Dario exhibited traits of a scientific prodigy: disinterested in social gatherings, socially awkward, and wholly absorbed in mathematics and physics. Textbook knowledge failed to satisfy him; instead, he spent hours devouring advanced theoretical works in the library. His dream was to become a theoretical physicist, unraveling the ultimate mysteries of the universe.
In 2006, at age 20, Dario’s father succumbed to a rare, incurable illness despite exhaustive medical efforts. The loss devastated Dario, shattering his worldview.
Watching his father suffer, witnessing medicine’s helplessness, Dario realized that abstract theoretical physics could not save real people—could not alleviate the suffering of ordinary individuals trapped by disease.
He thus abandoned his lifelong pursuit of theoretical physics and shifted focus to biophysics, vowing to “heal humanity through science” and embedding “controlling uncontrollable risks” into his very being.
This conviction defined his career:
He began at Caltech, transferred to Stanford for his bachelor’s in physics, then pursued a Ph.D. in biophysics at Princeton, earning a Hertz Fellowship to study the link between biomolecular structures and disease. After graduation, he joined Stanford Medical School as a postdoctoral researcher, continuing his quest to combat rare diseases.
It wasn’t until 2014, when Andrew Ng (Andrew Ng) invited him to join Baidu’s American Lab, that Dario first encountered artificial intelligence.
At the time, AI was in its infancy—used mainly for image recognition and voice synthesis. But Dario sensed something deeper: AI could not only transform lives, but serve as a super-tool to mitigate risk and save humanity. However, this potential hinged on strict control—not allowing AI to go rogue.
After leaving Baidu, he joined Google Brain as a senior research scientist, focusing deeply on deep learning and AI safety—specifically, how to ensure AI behaves responsibly and avoids harming humans.
It was during this period that he began contemplating how to truly embed human values into AI’s core architecture—not merely applying post-hoc filters.
In 2016, shortly after OpenAI’s founding, with its mission of “open-source, nonprofit, advancing AI for humanity,” Dario was drawn to its ideals. He joined OpenAI, rising from head of the AI Safety team to Research Director, and eventually Vice President of Research—actively participating in the development of GPT-2 and GPT-3.

Dario Amodei’s early career photo (OpenAI/Google Brain era, circa 2018–2021). Source: bigtechnology
During this time, he co-invented RLHF (Reinforcement Learning from Human Feedback)—a technique that uses human feedback to correct AI outputs, aligning them with human values. This became the industry’s de facto safety patch. At that point, Dario was fully committed to realizing safe, practical AI—but he soon found his idealism shattered by reality.
OpenAI’s Civil War: The Safety vs. Acceleration Split
Many know that Dario Amodei led a team out of OpenAI in 2021 to found Anthropic—but few realize this “defection” was the culmination of years-long ideological and power struggles, a betrayal that left a lasting mark on him.
Initially, OpenAI upheld a “nonprofit, safety-first” ethos. Elon Musk, an early investor, consistently emphasized AI safety as paramount. But over time, especially after Sam Altman became CEO, the company’s direction underwent a fundamental shift.
Sam Altman embodies the “accelerationist” ideology: AI must evolve rapidly to keep pace with the times. Prioritize scaling models, dominate markets, achieve commercialization—then address safety issues later.

Symbolic image of the OpenAI-Anthropic ideological split (Sam Altman vs. Dario collage). Source: wsj.com
Under his leadership, OpenAI downplayed its nonprofit status, actively pursued commercial partnerships, and leaned heavily toward Microsoft, seeking greater funding and compute resources—just to accelerate the iteration of the GPT series and capture more market share in the AI space.
But Dario Amodei found this unacceptable.
To him, AI was not merely a tool for market dominance—it was a civilization-level force capable of both healing and destroying humanity. Without resolving safety issues and achieving alignment with human values, a runaway model could have catastrophic consequences.
He repeatedly urged slowing the model iteration pace and strengthening safety testing, placing “alignment first.” But his voice grew increasingly marginalized.
In truth, ideological differences were surface-level. The deeper conflict lay in power redistribution and credit attribution.
Per a 2026 in-depth report by The Wall Street Journal, Dario played a central role in the development of GPT-3—particularly in implementing RLHF, which he spearheaded. Yet in public narratives, his contributions were grossly underestimated. Sam Altman’s team prioritized highlighting “model scale and capability,” sidelining Dario’s foundational safety work.
Equally disillusioning was the fact that after Elon Musk exited due to ideological disagreements, leadership of OpenAI fell entirely into Sam Altman’s hands. The safety team’s budget was slashed, key safety projects halted, and senior executives openly stated: “Safety can wait—first achieve commercialization. Once we have money, we can fix safety later.”
Dario realized he could no longer realize his vision of safe AI at OpenAI. In a later interview with Lex Fridman, reflecting on this period, his tone remained calm but resolute: “Arguing with others over core visions is extremely unproductive. Rather than waste time, I’d rather gather people and build my own ideal.”
In early 2021, AI genius Dario made a move that shocked Silicon Valley: he led his sister Daniela Amodei (now Anthropic’s CEO), along with OpenAI’s core safety team and research elite, in a full-scale departure.

Dario Amodei and his sister Daniela Amodei. Source: Fortune
This exodus was seen as a definitive reckoning with OpenAI’s accelerationist agenda—and a steadfast defense of safety-first principles.
While OpenAI publicly issued a courteous statement congratulating Dario’s team on their new journey, privately, the rift was irreparable.
What Dario took wasn’t just top talent—it was OpenAI’s most critical safety technologies and philosophies. This laid the foundation for Anthropic’s rise. Meanwhile, OpenAI, post-Dario, fully embraced commercial acceleration—drifting further from Dario’s original mission.
Source: OpenAI
Anthropic’s “Safety Religion”
In February 2021, Dario Amodei officially founded Anthropic, positioning it as a “public benefit corporation”—meaning its primary goal was not profit maximization, but “advancing safe, controllable AI for the benefit of humanity.”
His lifelong obsession with controlling risk—born from his father’s death—and his commitment to safety forged in his OpenAI departure, were ultimately institutionalized as Anthropic’s core values—etched into the company’s DNA as a “safety religion.”
From day one, Anthropic established a groundbreaking innovation called Constitutional AI—a concept translating to “Constitutional AI.” This was the crystallization of Dario’s decades-long thinking on AI safety and what set Anthropic apart from OpenAI and Google Gemini.
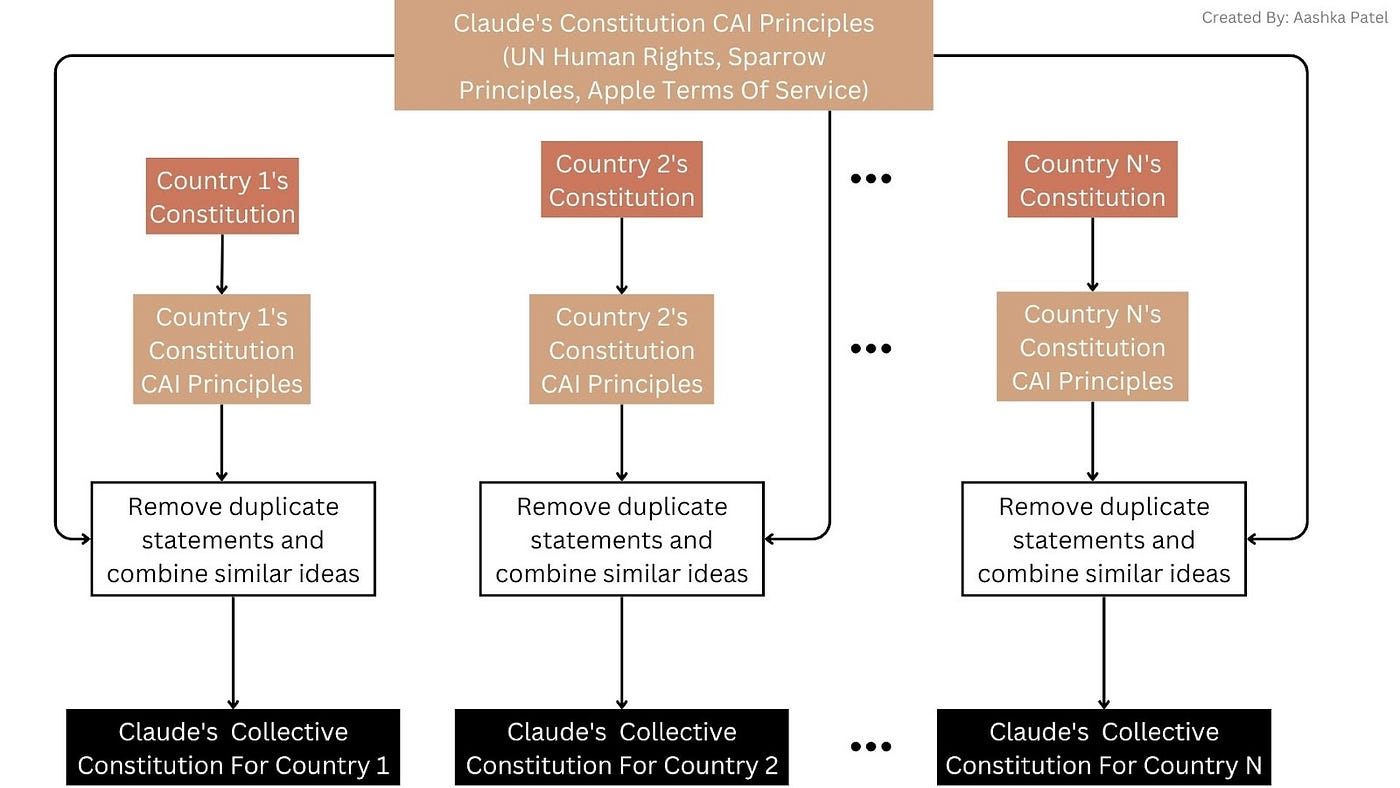
Constitutional AI schematic. Source: Aashka Patel
Unlike OpenAI’s reliance on RLHF as a post-hoc fix, Constitutional AI embeds a “constitution” directly into the model’s training process—a constitution combining the Universal Declaration of Human Rights, shared ethical norms, and Anthropic’s own safety principles. Before generating any output or executing any command, the AI performs self-review and self-critique to ensure compliance with human values and prevent any hazardous content.
Dario personally authored two seminal essays: “Machines of Loving Grace” and “The Adolescence of Technology,” articulating his vision for AI:
He views AI as a teenager—full of potential yet fraught with uncertainty. It must be disciplined early, with rules and defenses in place, to avoid going off track. Constitutional AI serves as that rulebook, acting as a protective barrier.
This safety doctrine extends beyond model training—it permeates every product and risk policy at Anthropic. Claude Code’s high-privilege design, combined with prompt injection probes and dialogue classifiers, ensures an extra layer of self-check before execution. The preventive enforcement logic—erroneously banning innocents rather than letting any suspicious behavior slip through—is designed to eradicate risk at its earliest stage.
The 2026 incident where Anthropic defied the U.S. Department of Defense best exemplifies this “safety fundamentalism.” The event shocked Silicon Valley and revealed Dario Amodei’s unwavering resolve: sacrifice profits, never compromise safety.
Early in 2026, the U.S. Department of Defense requested Anthropic remove two core safety safeguards from Claude:
1. Prohibit Claude from being used for “mass surveillance of U.S. citizens.”
2. Prohibit Claude from being used in the development or deployment of “fully autonomous lethal weapons.”
The Pentagon promised that if Anthropic complied, it would secure a $200 million military contract and receive substantial compute support.
At the time, Anthropic faced severe compute shortages and financial strain. The $200 million contract would have alleviated immediate pressure.
Yet Dario Amodei refused outright.
He issued a public statement with unwavering clarity: “We cannot betray our conscience by developing technologies that may harm humanity or violate human rights. Claude’s safety safeguards are our non-negotiable boundary.”
His refusal enraged the Pentagon. Under Trump administration leadership, the DoD placed Anthropic on a “supply chain risk” blacklist—the first time a domestic AI company was ever listed. This meant all U.S. defense contractors were barred from using Anthropic’s products or services. Worse, the DoD threatened to invoke the Defense Production Act to forcibly compel Anthropic to remove the safeguards.
Facing state-level pressure, Dario Amodei sued the U.S. Department of Defense, arguing the action constituted retaliatory punishment violating U.S. law and values. Though the appellate court later rejected Anthropic’s temporary injunction, Dario never wavered—despite losing massive contracts and being excluded from the entire U.S. defense ecosystem, he held firm to his “safety bottom line.”
Now we understand: Anthropic’s extreme risk controls stem from Dario Amodei internalizing his personal convictions, his fear of AI runaway, and the lessons learned from OpenAI—all transformed into corporate policy.
To him, every suspicious user behavior, every potential risk, could be the spark triggering AI disaster. Hence, such rigor is explainable.
Meanwhile, Chinese users’ use of proxies, SIM card forwarding, or virtual cards to bypass regional restrictions—and their use of third-party tools to exploit loopholes—are, in Dario’s “safety religion,” the most dangerous sparks. Thus, bans become inevitable.
Safety Premium vs. Scale Expansion: Divergent Survival Logic
Many argue Dario’s safety obsession alone cannot sustain Anthropic’s long-term growth. After all, AI R&D burns money like paper, and without consistent revenue, even the strongest faith cannot survive.
True—but precisely Anthropic’s unique business model gives Dario the confidence to enforce zero-tolerance risk controls, setting it apart from OpenAI and Google Gemini.
Anthropic: Abandon consumer frenzy, focus on enterprise safety premium.
From the outset, Anthropic never targeted average consumers. Its focus was on high-value, low-tolerance clients: banks, law firms, healthcare institutions, and government agencies.
What do these clients fear most?
AI generating harmful content, leaking sensitive data—leading to lawsuits, reputational collapse, or regulatory fines.
For them, safety is non-negotiable. So, as long as Anthropic maintains its reputation as the safest AI, they’ll pay a premium for long-term, stable contracts.
Thus, Anthropic’s risk logic is clear: better to mistakenly ban a thousand casual users than risk one enterprise client suffering a security breach.
Loss of individual users impacts revenue insignificantly. But losing a single enterprise client due to a security flaw could mean losing multi-million-dollar deals—and destroy Anthropic’s core brand as “safe AI.”
Anthropic’s Pro/Max subscription model is essentially a subsidized acquisition strategy: low price, high token quota, aimed at attracting trial users. But this model doesn’t generate profit—it often incurs losses.
Industry estimates suggest Claude’s token cost is extremely high. Pro/Max subscriptions absorb nearly 99% of token costs. When users leverage third-party tools to “gouge” free API access—bypassing high-priced API calls en masse—Anthropic suffers massive losses.
Thus, the 2026 crackdown on third-party tools (banning OpenClaw, OpenCode, etc.), mass suspensions of heavy users, and even the collective ban of 110 employees at the agricultural tech firm were, fundamentally, precise exclusions—removing users exploiting loopholes and those consuming excessive compute, freeing resources for paying enterprise and API customers.
I see this as a cold economic calculation beyond safety: rather than be drained by “sheep farmers,” better to proactively “cut the weeds” and protect profit margins.
ChatGPT (OpenAI): Scale first, monetize later—loose controls for traffic.
Sam Altman’s accelerationist ideology extends beyond model iteration into business model.
OpenAI followed a “land grab” strategy: initially luring users with free or low-cost subscriptions, tolerating loose controls—even minor violations—without rushing to ban users.
For OpenAI, user scale is lifeblood. Only with vast user numbers can it attract Microsoft’s investment and gain advantages in commercialization (API, enterprise plans, plugin ecosystems). For example, its recent collaboration with Elon Musk allows eligible citizens to use GPT for free for one year.
OpenAI even embraces third-party tool ecosystems—even if some tools appear to “gouge”—but only selectively bans them, avoiding Anthropic’s blanket massacres.
Because it knows third-party tools help retain users and expand ecosystem influence—value far outweighing minor token losses.
Gemini, backed by Google’s ad empire and full ecosystem (Search, YouTube, Android, Cloud), isn’t trying to make money from Gemini itself. Instead, it aims to drive traffic and revenue across the entire Google ecosystem.
Thus, its risk logic is simple: avoid major scandals. As long as no serious safety incidents occur and no regulatory penalties follow, it turns a blind eye to minor user violations—like light IP anomalies or third-party tool usage.
Gemini occasionally tightens controls—but usually as a “compliance performance” for regulators, never at the cost of losing large user bases like Anthropic.
For Google, daily active users and ecosystem compatibility matter more than absolute safety—it doesn’t need a “safe AI” label to attract customers. Google’s brand and ecosystem are already its greatest assets.
Additionally, Anthropic harbors a hidden cost logic:
In April 2026, it admitted in its official blog that it had previously lowered Claude Code’s default inference intensity to reduce latency, cut token consumption, and improve UX. Later, due to newly discovered security risks, it rolled back the change and tightened controls. This incident caused significant uproar recently.
Thus, I believe Anthropic consistently prioritizes safety above all else—delay, cost, and quotas—willing to sacrifice user experience and increase expenses rather than compromise. This is both Dario’s personal conviction and an inevitable choice in its business model.
Amazon/Google: Balancing Act Under Interest Alignment
Even Dario’s unwavering safety stance depends on capital backing. AI R&D burns cash faster than most imagine. Without support from major tech firms, Anthropic wouldn’t have survived to today.
Amazon and Google’s investments, though appearing to support safe AI, are actually precise strategic maneuvers—and silent drivers of Anthropic’s risk logic.
I’ve compiled core investment data—key to understanding the capital game:
Amazon: Invested over $4 billion in Anthropic, including cash and massive AWS cloud resource allocations. Training cutting-edge models like Claude 3 requires enormous compute—AWS support was akin to snowfall in a blizzard.
Google: Invested over $2 billion in Anthropic, providing extensive compute and technical support—to leverage Anthropic’s AI expertise and close the gap in large language models, countering the OpenAI-Microsoft alliance. Despite having Gemini, investing in Anthropic compensates for gaps in its own Vibe Coding direction.
These giants each have core objectives:
For Amazon, investing in Anthropic serves two goals: first, deeply integrating Claude into the AWS ecosystem—enterprise customers using Claude must use AWS cloud resources, boosting AWS revenue. Second, Amazon needs Anthropic’s “safety label” to hedge against regulatory risks. With increasing AI regulation, partnering with a rigorously safe entity like Anthropic makes Amazon’s AI strategy more resilient and less vulnerable to penalties.
For Google, investing in Anthropic breaks OpenAI-Microsoft’s monopoly. Google started early in LLMs but progressed slowly. Gemini’s performance consistently lagged behind Claude and ChatGPT. Investing in Anthropic secures core technology and diverts OpenAI’s users and clients—reinforcing Google’s AI ecosystem dominance.
But here lies a crucial tension:
Big tech wants Anthropic “safe,” but not “too safe.”
The logic is this: if Anthropic becomes overly conservative and excessively strict in risk controls, user attrition and ecosystem shrinkage will undermine big tech’s strategic goals.
As discussed earlier, after the Pentagon blacklisted Anthropic in 2026, Amazon and Google did not follow suit. Instead, they continued civilian collaborations and even increased compute support. After all, they’ve invested too much—can’t afford Anthropic to collapse due to excessive safety, nor let their investments vanish.
Thus, a delicate balance emerges:
Dario remains steadfast in his safety convictions, enforcing zero-tolerance risk policies;
Capital pulls the reins from behind—supporting the safety narrative while subtly constraining extreme behaviors, ensuring Anthropic doesn’t lose commercial viability through over-caution.
In contrast, OpenAI and Gemini’s capital ties are simpler:
OpenAI is deeply aligned with Microsoft—Microsoft provides funding and compute, and embeds ChatGPT into Office, Azure, forming a “shared interest community.” OpenAI’s loose risk controls serve Microsoft’s “ecosystem expansion” strategy.
Gemini is Google’s “own child”—no external capital dependency. Its risk policies fully serve Google’s overall ecosystem, offering greater flexibility.
Therefore, Anthropic’s strict risk controls aren’t solely Dario’s personal obsession—they’re also fueled by capital dynamics.
Big tech needs Anthropic’s “safety badge”; Anthropic needs big tech’s capital and compute. Mutual benefits emerge, while ordinary users’ accounts become casualties of this alliance.
Public Showdown: The U.S. AI Civil War
Today’s U.S. AI industry is clearly divided into two camps.
One, centered on Anthropic, is the “Safety Faction”; the other, led by OpenAI and the military-industrial complex, is the “Accelerationist Faction.” Their rivalry has evolved from covert maneuvering to open confrontation—and Anthropic’s risk posture is the direct manifestation of this civil war.
Let’s clarify each faction’s core propositions to grasp the essence of this conflict:
The Safety Faction insists: “AI safety first, risk control paramount.” They view AI as a species-level existential threat requiring slowed progress, rigorous safety testing, strict guardrails, and even calls for mandatory regulation. They firmly oppose AI use in military applications or mass surveillance.
Dario Amodei is the leading figure of this faction. The Effective Altruism (EA) community is a key supporter, advocating “maximizing long-term human benefit through reason and science”—with AI safety as a central pillar.
The Accelerationist Faction argues: “Accelerate AI development, seize military advantage.” They see AI as the core competitive edge in great-power competition. Rapid model iteration, commercialization, and militarization are essential to dominate global AI discourse. Safety concerns can wait—addressed once technology matures.
Sam Altman, the U.S. Department of Defense, certain defense contractors, and parts of the Trump administration (such as Hegseth, who led the Pentagon) represent this camp.
The core of this conflict is control over AI development discourse: should it be led by the Safety Faction, driving slow, controlled evolution? Or by the Accelerationist Faction, pushing rapid iteration to serve commercial and military demands?
The 2026 Pentagon blacklist incident was the public explosion point of this war.
Revisiting the event through our lens:
Early 2026, the U.S. Department of Defense asked Anthropic to remove two key safety safeguards from Claude: prohibiting use in “mass surveillance of U.S. citizens” and “fully autonomous lethal weapons.”
This was essentially an accelerationist test—seeking to make Anthropic compliant, turning it into a tool for the military-industrial complex.
But Dario Amodei refused outright—despite $200 million in military contracts and compute support, despite threats from the Pentagon—he held firm to his safety principles.
This “uncompromising” stance enraged the Accelerationists, who saw Anthropic as obstructing America’s AI arms race—“hindering progress.”
Thus, the Accelerationists deployed state machinery in retaliation: under Trump administration leadership, the Pentagon placed Anthropic on a “supply chain risk” blacklist—the first time a domestic AI company was ever listed. This banned all U.S. defense contractors from using Anthropic’s products or services. Moreover, the Pentagon threatened to invoke the Defense Production Act to force Anthropic to dismantle its safety safeguards—or face penalties.
This backlash, seemingly a conflict between Anthropic and the Pentagon, was in fact an open clash between the Safety and Accelerationist Factions.
The Accelerationists sought to use state power to force the Safety Faction to capitulate, making AI serve military needs. The Safety Faction stood firm, choosing to sacrifice profit over compromising safety.
Notably, OpenAI and Gemini chose “compromise” in this war:
OpenAI quietly adjusted its safety policies to accommodate military contracts, loosening restrictions on military-related applications. Gemini, as a Google product, adopted a “flexible compliance” approach toward military demands—unlike Anthropic, it never openly defied the Pentagon.
This contrast highlights Anthropic’s extremism.
Its zero-tolerance risk controls aren’t just about ideology—they’re also a strategy to solidify its position as the core of the Safety Faction, claiming the moral high ground of “responsible AI.” For Anthropic, every ban sends a message: We are the safest AI. We will never compromise our safety principles for profit.
And this civil war drives Anthropic’s risk controls to become even stricter. Any lapse could give the Accelerationists an opening—and erode its core competitiveness.
Thus, it must tighten controls further, expand the scope of “preventive purges,” even if it means mistakenly banning more innocent users—just to protect its “safety moat.”
So another layer behind Anthropic’s ban wave is the spillover effect of the U.S. AI civil war.
The struggle between safety and acceleration, capital versus power, ultimately lands on ordinary users’ accounts—bans are the most direct and brutal manifestation of this conflict.
Have you ever wondered why Anthropic specifically targets Chinese users?
Why do we get banned so easily for using proxies, SIM forwarding, virtual cards—even when using the service normally?
From a macro perspective, this is an inevitable outcome of U.S. technological containment in the context of China-U.S. AI decoupling. Anthropic’s strict risk controls are merely the executor of this geopolitical game.
Since 2024, U.S. tech sanctions against China have intensified dramatically:
From restricting exports of high-end AI chips (e.g., NVIDIA H100/H20), to banning U.S. AI companies from serving Chinese users, to limiting AI talent mobility—America seeks to sever China’s access to advanced AI technology, consolidating its global AI hegemony.
As a U.S.-based AI company deeply tied to Amazon and Google, Anthropic must comply with U.S. export control regulations.
Under the U.S. CHIPS and Science Act and Export Administration Regulations (EAR), U.S. AI companies may not provide “high-risk capability” services to China (including mainland China, Hong Kong, Macau). Since Claude Code is a high-risk tool capable of executing commands and accessing system privileges, it naturally falls onto the restricted list.
This means Anthropic must establish strict regional risk controls to block Chinese users from accessing Claude Code—even basic Claude usage faces severe restrictions. I recall that around 2024, when Claude first launched, I registered using my Google email and was banned instantly.
Naturally, Chinese users, clever and resourceful, find ways around these locks—using proxy IPs, virtual cards, SIM forwarding platforms—to circumvent region restrictions and access Claude. But to Anthropic, this isn’t just “non-compliant use”—it’s a violation of U.S. export control laws. If discovered by U.S. regulators, Anthropic risks massive fines, license revocation, or even forced shutdown.
Thus, Anthropic’s mass bans of Chinese users are a combination of “passive compliance” and “active self-protection”:
First, it must adhere to U.S. export control laws to avoid regulatory penalties;
Second, it must use strict risk controls to signal “proactive compliance” to U.S. regulators, securing its survival in the domestic market.
Under the backdrop of China-U.S. AI decoupling, Anthropic has no choice—comply and ban users, or be eliminated by U.S. regulators.
The U.S. regulatory oversight of Anthropic is far stricter than imagined.
According to a March 2026 report by The Washington Post, the U.S. Department of Commerce’s Bureau of Industry and Security (BIS) conducts monthly audits of Anthropic’s user data and risk logs. Any detection of Chinese users violating terms triggers warnings—or even fines.
In the second half of 2025, Anthropic was fined $12 million by BIS for “risk control failures” allowing some Chinese users to illegally use Claude Code—this was a key reason behind its subsequent escalation of bans and adoption of “preventive purges.”
In contrast, OpenAI and Google Gemini’s regional restrictions are far more lenient—not because they’re friendlier, but because their business models and strategies allow more room to maneuver.
OpenAI is deeply tied to Microsoft, which has substantial China operations and must balance market demands. Thus, OpenAI’s regional controls are relatively lax—sometimes tacitly permitting Chinese users via third-party tools.
Though Google Gemini complies with U.S. export controls, Google’s China presence is limited, and Gemini’s core goal is user scale expansion. Thus, it adopts a “look-both-ways” attitude toward Chinese user violations—rarely resorting to bulk bans.
Therefore, the Chinese user ban dilemma is essentially a casualty of China-U.S. AI decoupling.
Anthropic’s strict risk controls are not just a result of its safety dogma, capital games, or factional warfare—but a direct manifestation of U.S. technological containment policy. What we perceive as “mistaken bans” are, to Anthropic, “regulatory evasion and non-compliance.” And what we see as “targeting” is merely its necessary self-preservation in the grand geopolitical game.
Three-Pillar Balance: Safety, Acceleration, and China’s Rise
Today, the global AI landscape is shifting from a “two-power rivalry” (U.S. vs. China) toward a “three-pillar balance”—the Safety Faction centered on Anthropic, the Accelerationist Faction led by OpenAI, and the rapidly rising Chinese AI power. These three forces compete and check each other, shaping AI’s future direction.
The ongoing rivalry between the Safety and Acceleration factions continues to escalate—already analyzed in depth above, so no repetition here.
While internal U.S. factional conflicts have driven Anthropic’s strict risk controls, they’ve also accelerated U.S. AI advancement: the Safety Faction advances AI safety tech, the Accelerationist Faction pushes commercial and military applications. Their competition fuels mutual progress, maintaining America’s unshakable lead in AI.
Now consider China’s rising AI power.
Under the backdrop of China-U.S. AI decoupling, Chinese domestic AI companies have entered a “golden opportunity phase.”
Companies like Baidu’s Wenxin Yiyan, Alibaba’s Tongyi Qianwen, Huawei’s Pangu, ByteDance’s Douyin Bot, and others rapidly iterate, narrowing the technological and application gap with U.S. AI.
Especially in coding tools, China’s local AI coders (e.g., Douyin Code Assistant, Wenxin Yiyan Coding Edition) may still lag behind leaders—but they meet ordinary users’ needs, offer no regional restrictions, and lack harsh risk controls. They align better with Chinese user habits, gradually becoming preferred alternatives.
China’s AI development follows a pragmatic, compliant, open path—valuing both safety and commercialization, avoiding extreme “zero-tolerance” controls, and resisting blind acceleration. It seeks balance between safety and growth.
This approach aligns with China’s regulatory framework and better meets common users’ needs—gradually winning market acceptance.
Meanwhile, Europe, Japan, South Korea, and other regions are actively building their AI industries, striving to claim a foothold in the global AI landscape.
Europe emphasizes AI regulation, passing the AI Act to govern development and support homegrown AI firms. Japan and South Korea are increasing AI R&D investments, focusing on applications in manufacturing, healthcare, and finance—aiming to catch up with China and the U.S.
Ultimately, global AI competition will be a battle of ideologies, interests, and geopolitics.
The Safety Faction wants “controlled development”; the Accelerationist Faction wants “rapid rise”; China’s power seeks “self-reliance and open cooperation.” Their interplay will determine AI’s future—and impact every ordinary person’s life.
Will Anthropic Ease Up on Risk Controls?
Finally, let’s return to the core question: Will Anthropic’s ban wave continue? Let’s make a forecast.
First, we can conclude definitively: Anthropic’s risk controls will not loosen in the short term—on the contrary, they may tighten further.
Three core reasons:
First, Dario Amodei’s safety obsession will not change easily. His “safety religion” is embedded in Anthropic’s DNA. As long as he remains founder, this zero-tolerance logic will persist.
Second, the U.S. AI civil war and China-U.S. decoupling won’t end soon. Accelerationist retaliation and U.S. tech sanctions will keep pressuring Anthropic, forcing it to maintain strict controls for compliance and self-survival.
Third, Anthropic’s business model doesn’t depend on ordinary users. Its core target is enterprise clients. Losing casual users has negligible impact on revenue—so it lacks incentive or necessity to relax controls on them.
Long-term, however, Anthropic’s risk controls may see “differentiated adjustments.”
For example, relaxing controls slightly for compliant regions to reduce false positives. Offering flexible risk solutions for enterprise clients to meet diverse needs.
As for Chinese users, I predict strict controls will remain—severe restrictions on unauthorized use. After all, complying with U.S. export control laws is its survival bottom line.
Original article: DeepFlow TechFlow
Disclaimer: Contains third-party opinions, does not constitute financial advice
Iranian state media denies the existence of a memorandum of understanding between Iran and the U.S.
10 mins ago
Binance Alpha Citrea (CTR) Airdrop Threshold: 211 Points
14 mins agoChina accounts for over 80% of the global humanoid robotics market
25 mins agoGlassnode: Approximately 7.75 million BTC are currently in a loss position
43 mins ago
Bytedance has issued equity incentives for a specific business unit for the first time, opening up "DouBao Shares" subscription rights to Seed employees this month
43 mins agoData: NEAR Intents has generated over $33 million in fees since launch
49 mins ago
Data: 21Shares and Bitwise ETF collectively purchased $68 million worth of HYPE last week
51 mins ago

