ChainThink
Stay ahead, master crypto insights
3 border-line images, top the Kaito Chinese area in 24 hours
3 border-line images, top the Kaito Chinese area in 24 hours

2025-05-08 09:30
Original Title: "Kaito Algorithm's Comeback Experiment: How to Reach the Top of the Chinese Zone in 24 Hours with 3 Edge-Case Posts"
Original Author: yunfeng, ChainThink
Jesse's InfoFi Practical Report
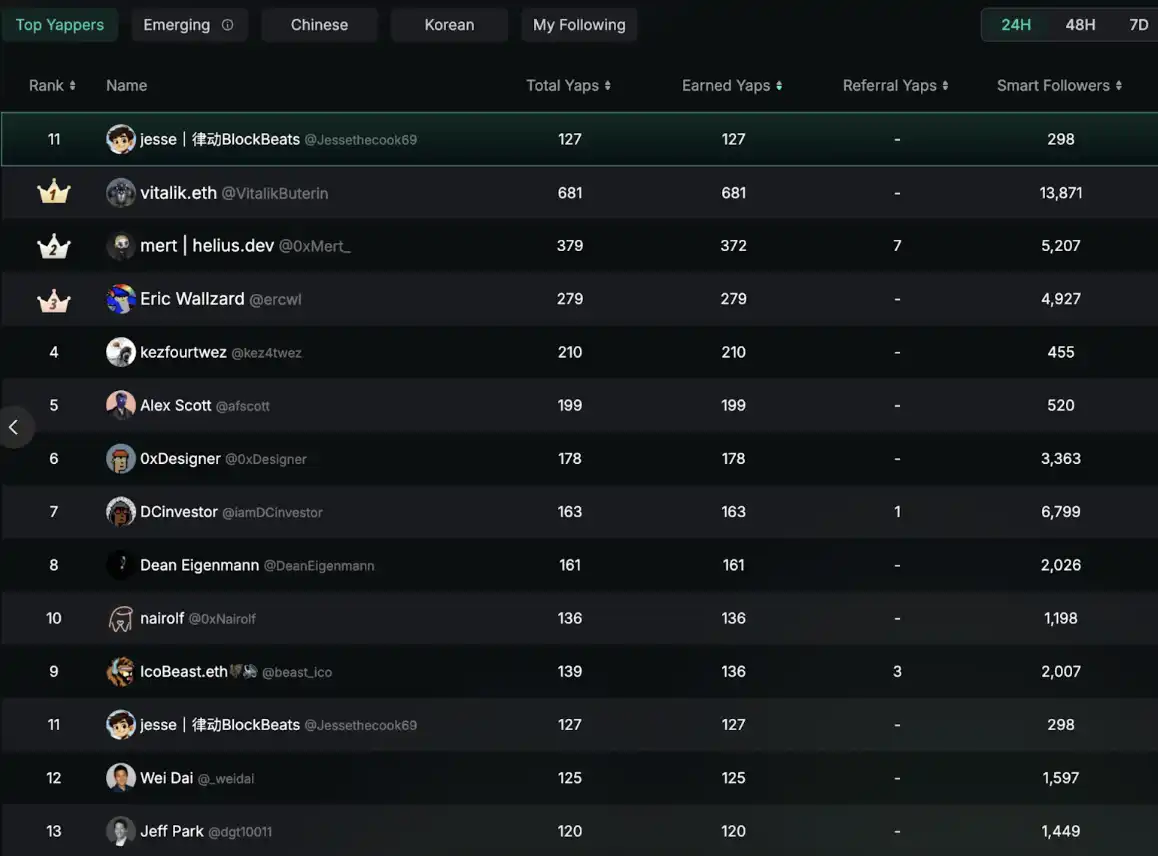
Recently, Jesse conducted an experiment on X (formerly Twitter): posting three pieces of content that were between valuable information and pure spam — "edge-case" crypto content — to test the boundaries of Kaito's Yap scoring algorithm. Unexpectedly, within less than 24 hours, his account @jessethecook69 climbed to the ninth position on the Kaito Yapper ranking and took the top spot in the Chinese zone. This phenomenon of achieving rapid rankings with non-high-quality content raises questions about whether Kaito's claimed AI content scoring algorithm is truly fair and strict as advertised, or if there are exploitable loopholes.
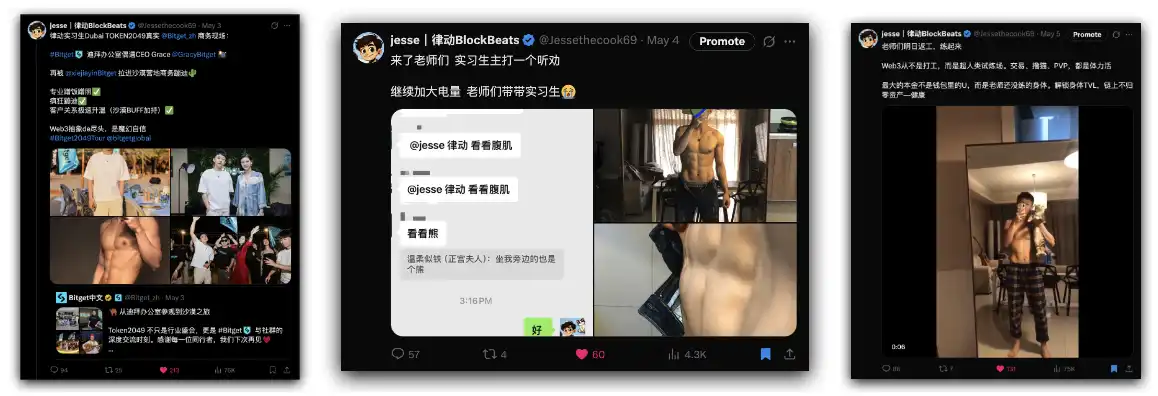
The following are the three edge-case tweets published in this experiment. These contents are close to daily life, quickly gaining a large amount of interaction through humor and visual impact.
In fact, there have been many similar doubts in the community. A Blockworks report mentioned that some users managed to score hundreds of Yap points by repeatedly replying the same word (e.g., "reply") under a tweet. Although the official may have fixed such loopholes soon, these cases are enough to spark discussion: Is Kaito's "InfoFi" model really able to fulfill its promise of rewarding high-quality information, or has it turned into a new traffic game in some cases?
To answer these questions, it is necessary to analyze the underlying principles of Kaito, understand how it uses the massive metadata provided by the Twitter API, combines large language models like OpenAI's ChatGPT for semantic analysis and trend judgment, and builds a decentralized information ecosystem through "social incentive" mechanisms such as Smart Followers and Yap points. Next, Jesse will analyze this issue from both industry significance and technical details perspectives.
InfoFi: Kaito's Platform Innovation and Industry Significance
Kaito's proposed InfoFi model is not only a technological and product innovation experiment, but also bringing structural impacts to the information dissemination mechanism and marketing paradigm in the crypto industry. In the past, crypto project marketing mainly relied on traditional methods: hiring PR agencies, collaborating with KOLs (crypto opinion leaders) to create buzz on social media. In this model, information was often opaque, inefficient in spreading, and led to a lot of "soft articles" and puff pieces. In contrast, Kaito's algorithm-driven community incentives are changing the rules of the game — the relationship between project teams, KOLs, and ordinary users is repositioned in a competitive environment based on content value and contributions.
Project Marketing Paradigm Shifts from "Push" to "Participation"
In the traditional model, project teams often viewed user attention as an ad space that could be purchased with money: paying big V's to post promotional posts, then leveraging their large fan base to spread the information. However, this push-based marketing has obvious risks:
· Difficult to measure effectiveness: How many of the KOL's followers are genuinely interested in the project? What is the conversion rate? The project team may spend a high budget, but only get inflated "buzz", with very few actual user conversions.
· Doubts about information credibility: Today's audience can easily distinguish which content is paid promotion, and usually remain cautious or even resentful towards such hard-sell ads.
Kaito's emergence has introduced a participatory viral transmission model: through "Yap-to-Earn," projects no longer need to concentrate marketing budgets on a few big V's, but instead integrate into Kaito's Yapper ranking system, allowing the community to voluntarily promote the project. For example, a new project wants to expand its buzz, can cooperate with Kaito to launch a community ranking for the project on the platform — all users' original content around this project participates in the point competition.
The actual effect is similar to a mass participation content creation contest. Users compete to study the project, publish in-depth analysis or unique insights, aiming to reach the ranking to gain returns; the project team gains a large amount of high-quality UGC (user-generated content) at a relatively low cost (such as promising token airdrops or prizes for top-ranking users). These contents are shared by users on public platforms like Twitter, often having more dissemination power and persuasiveness — after all, this is not cold advertising, but the real voices of community members (even with incentive factors, the content is user-created). This model is called "Proof-of-Attention" in the social version: those who rank high on the leaderboard are seen as providing high-value information, thus receiving deserved rewards.
Whether this approach is labeled as InfoFi or SocialFi, it is actually reshaping the way projects are propagated. Marketing is no longer entirely dominated by centralized teams, but becomes a community-driven collective creation. The role of the project team also changes from traditional ad sponsors to initiators and reward providers of community activities.
No Longer Just About Followers: How Small KOLs Can Rise Through Kaito?
In the InfoFi ecosystem, the role of traditional crypto KOLs also changes. On one hand, top KOLs still play a significant role: for example, figures like Vitalik, jesse.base, etc., still rank highly on the Yapper leaderboard, indicating that those with genuine insights and a large following can still lead the topic. On the other hand, these KOLs now face an open competition environment: every time they speak, their performance is objectively recorded and scored by the algorithm, with scores clearly visible. For genuine KOLs with valuable content, this is a positive incentive; however, those who previously relied solely on fame without producing substantial content may see their influence gradually weakened in the InfoFi mechanism. Because if they only post advertisement posts and don't get points, and don't actively participate in discussions, their ranking on the leaderboard will drop and they will be seen as "without substance." As a result, KOLs are forced to be more proactive and sincere in participating in community discussions, otherwise they may be overtaken by others.
Jesse observed that some mid-tier KOLs have already achieved "upgrades" through Kaito. They may not have as many followers as top V's, but due to their diligent production of high-quality content, they are ranked higher on the leaderboard, gaining exposure comparable to top V's. This challenges the traditional KOL influence structure: influence is no longer solely determined by follower count, but also by content value and reputation. It can be compared to a "influence mining" process — KOLs "mine" influence points (Yap) by continuously contributing high-quality information. Compared to relying solely on long-term follower accumulation, this model makes influence acquisition more multidimensional and dynamic.
At the same time, the monetization model of KOLs is also transforming. In the past, big V's mainly made money by promoting projects for payment. Now, they have another channel: accumulating Yap points to wait for future redemption (e.g., exchanging them for the platform token KAITO). In the short term, Yap points cannot be directly monetized, but they are given a high expected value (there is already a secondary market where this expectation is discounted). Since Yap is scarce and difficult to obtain, many KOLs invest time on Kaito to stay active, similar to early participation in "mining" to gain future benefits.
When some projects (like Berachain) target the Top Yapper on Kaito for airdrop rewards, KOLs have more motivation to maintain their top positions on the leaderboard to gain these additional benefits. This indirectly reduces the need for project teams to pay KOLs directly for advertising: instead of spending money to have big V's post an advertisement, they can allocate part of the budget as community rewards to encourage people to discuss on Kaito; KOLs can also benefit. In this way, the relationship between KOLs and project teams shifts from traditional client-vendor to partners jointly participating in community operations. KOLs must demonstrate their genuine insights about the project to gain community recognition, while project teams are happy to see KOLs drive more people to discuss their project. Both parties interact on an open platform, with more transparent and visible information.
Opportunities and Challenges for KOL Agencies
For KOL Agencies (KOL agents/representatives), the Kaito model is a double-edged sword. On one hand, it weakens some of the exclusive values that KOL Agencies previously held: project teams can directly use Kaito's data and rankings to find effective communicators without over-relying on agency resources. Kaito provides quantified KOL maps and performance rankings as references, enabling project teams to identify the most active communicators in specific fields and which users show high engagement and loyalty towards the project. This level of data transparency was previously only known to experienced KOL Agencies (based on long-term experience knowing which KOLs are good at driving conversions); now Kaito has made these indicators public and data-driven. Accurate KOL maps can improve the effectiveness of marketing campaigns and increase the value return for project teams — and building this map relies on cleaning and weighting massive data, which is one of Kaito's core competencies. If KOL Agencies continue to use old models, only providing vague KOL lists and rough strategies, their value is inevitably questioned.
But on the other hand, KOL Agencies are not entirely without opportunities. Alert agencies can choose to embrace Kaito, viewing it as a new tool to utilize. They can subscribe to advanced services like Kaito Pro, gain deep data insights, and thus develop more effective communication strategies for their clients. Through the Kaito platform, KOL Agencies can help project teams achieve communication goals more precisely, such as:
· Selecting KOLs: Referencing Yapper rankings, the number of Smart Followers (core followers), etc., to select the most suitable KOLs for collaboration.
· Planning topics: Using Kaito's analysis of industry trends to plan hot topics that incorporate the project into community discussions, guiding more users to participate in discussions.
· Monitoring results: Real-time monitoring of promotion effects, measuring the conversion of buzz through Yap point growth and leaderboard changes, and adjusting strategies accordingly.
· Rule optimization: Guiding project teams to make full use of Kaito's rule advantages, such as how to initiate Launchpad community votes (activities where the community votes to list projects), and when to incentivize the community to produce more related content. This role is somewhat similar to SEO consultants in the era of search engines — now it's InfoFi consultants, specializing in mastering the Kaito ecosystem.
In this process, the value positioning of KOL Agencies will shift from "resource intermediaries" to "strategy consultants," requiring them to deeply understand Kaito's algorithmic mechanisms and community operation strategies. It is foreseeable that some sensitive agencies have already started studying Kaito's scoring methods, seeking the keys to triggering high scores, in order to better serve their clients. Of course, it should be noted that Kaito's algorithms are constantly updated and optimized, and it is not easy to game the system with simple tactics, but there is still considerable room for optimization within the scope of compliance (for example, guiding real community discussions rather than fake screen flooding). Overall, Kaito presents challenges to KOL Agencies, but also provides new opportunities to seize the momentum: whoever masters and utilizes InfoFi tools well can continue to create value for clients in the new paradigm.
Improvement of Information Dissemination Quality and Algorithmic Challenges
The improvement of information dissemination quality in the industry by Kaito is evident. Through the InfoFi incentive mechanism, the previous pure advertisements and hype posts on social platforms have been suppressed, replaced by more detailed analyses and rational discussions. This has had a positive impact on the information environment of the entire crypto community: investors can see more insightful opinions, reducing the risk of being misled by meaningless noise; project teams can receive more genuine feedback and suggestions from the community, rather than just flattery or abuse. Attention is directed towards truly valuable information, significantly improving the effectiveness and value of the information flow.
However, this also conceals a worrying concern — the concentration of power under algorithmic control. As more industry exchanges move to platforms like Kaito, the platform algorithm itself has gained enormous influence. Like the concern that Google's search algorithm determines which websites can be seen, Kaito's algorithm is actually deciding which voices are amplified. Although InfoFi claims to be fair, the analysis above also mentions that it tends to favor users with existing reputations. This may lead to innovative ideas or counter-opinions that do not gain the approval of mainstream KOLs being difficult to spread; over time, could this form another "information cocoon"?
The possibility of Kaito making algorithmic adjustments for commercial interests should also be noted — for example, the algorithm may favor promoting cooperative project information (according to observations, the system seems to clearly encourage users to discuss projects that have integrated with Kaito). As a crypto community that values decentralization, we should be vigilant against algorithmic monopolies and urge Kaito to maintain transparency and fairness in rule-making. Kaito has already publicly released some FAQs and basic principles, but the specific scoring details remain a black box. In the future, perhaps more DAO-like governance is needed, allowing the community to participate in supervising the evolution of the algorithm, ensuring that the InfoFi model truly fairly incentivizes high-quality information.
Technical Principles: The Behind-the-Scenes Mechanisms from Data Acquisition to AI Analysis
Twitter API Data Acquisition: Content Foundation and Challenges
As a platform focusing on crypto news, Kaito first needs to continuously acquire data from Twitter (X). Through the official API interface, Kaito automatically captures metadata of each tweet, such as text, release time, likes, and retweets, associates it with author information and interaction user lists, laying the foundation for subsequent algorithmic judgments.
For example, a tweet discussing Bitcoin would have its content, release time, interaction heat, and the influencer status of the poster recorded by Kaito; if an industry big V participates in the interaction, the algorithm would determine that the information has higher value. The premise of achieving this is efficient scheduling and utilization of the Twitter API.
Since Elon Musk took over, Twitter has significantly increased API usage fees: the starting price for enterprise-level interfaces is as high as $42,000 per month (only capable of querying about 50 million tweets). To track the dynamics of the entire crypto circle, the required query volume far exceeds this level, posing a huge cost pressure for startups. Although Kaito's official has not detailed specific responses, it can be imagined that the team must carefully manage each API call. It is likely that they have adopted the following strategies to control data acquisition costs:
· Focus on key areas: Prioritize capturing data from core accounts and topics in specific crypto fields, rather than indiscriminately crawling the entire platform, to save on query quotas.
· Batch queries and caching: Use batch queries and caching techniques to reduce repeated requests and minimize the number of API calls as much as possible.
· User authorization crowdsourcing: Some analysts speculate that Kaito requires users to bind X accounts to obtain authorization tokens, outsourcing some data capture tasks to users themselves, thereby bypassing official frequency limits.
In Jesse's view, these strategies are all aimed at minimizing data costs and risks while not affecting core functionality, ensuring that the InfoFi model has a stable data source.
ChatGPT Content Analysis: AI Empowering Information Value
Obtaining massive data is just the beginning, and Kaito's more important weapon is calling upon OpenAI's ChatGPT model to perform semantic analysis and quality assessment of content. Simply put, Kaito lets AI act as an "information connoisseur" and "filter." Whenever a user posts on X, the backend algorithm analyzes the content intelligently, including identifying the topic discussed in the tweet, assessing the content's value, and determining if there are any botting or cheating behaviors.
With advanced large language models, Kaito claims to be able to transcend language barriers, understanding and rating multilingual content such as English and Chinese equally, without favoritism. This means that regardless of the language used by the user to express their views, they can theoretically receive the corresponding Yap point rewards.
ChatGPT models are also used to identify spam and filler content. According to Kaito's official and community introduction, they place great emphasis on the originality and depth of content, and will not give high scores just because of high interaction data, nor will they reward purely botting or meaningless interactions. For example, even if a tweet mechanically repeats keywords like "cryptocurrency" or "Crypto," it cannot trick the AI to gain score increases, because the system prioritizes real, meaningful discussions.
Jesse's personal experiment raised doubts about the ideal state. In the experiment, I posted three edge-case cool images with only a few words, unexpectedly earning nearly 190 Yap points. The comment sections of these three tweets were all filled with complimentary remarks, with almost no substantive information.
Such content with so much water could still get such high points, which makes one wonder: due to cost considerations, Kaito's algorithm may not have performed a deep semantic analysis on each tweet, or may have taken some simplification strategies in the scoring process. Perhaps the current system is more based on basic interaction data to determine scores, and has made trade-offs in semantic understanding. This discovery made Jesse question the rigor of Kaito's algorithm: what extent has the claimed intelligent content scoring mechanism been implemented?
Smart Followers Mechanism: Influence Assessment Based on Quality Over Quantity
While Kaito introduced AI analysis in the content aspect, it did not ignore the "network" factor. The platform's innovation lies in introducing the "Smart Followers" (intelligent followers) mechanism, establishing a crypto social graph, and incorporating the quality of followers into content value assessment. For Kaito, who is following you is more important than how many followers you have. Those who mutually follow and form a core group of crypto circles are categorized as Smart Followers (core followers).
If a writer's follower list is full of big names (e.g., Vitalik Buterin, Binance CZ, etc.), then the writer's influence is obviously extraordinary, and the maximum score he can get from publishing content will also be correspondingly higher.
This social graph model allows Kaito to more objectively evaluate the "internal diffusion" of each tweet: whether it is spreading among outsiders or reaching the vision of industry elites. For example, a message may have 100 retweets, but if most of them come from mutual-follow small accounts, its actual value may be limited; while another message has only 10 retweets, but includes participation from heavyweights like Vitalik, the latter's "value" is obviously higher. For these two situations, Kaito will assign completely different Yap points, avoiding judging solely by the number of retweets or likes.
From the actual results, accounts that rank high on the Yap leaderboard are often not the ones with the most followers, but more likely the ones recognized by top KOLs. As a report states, Kaito does not rely on traditional metrics like follower count or page views, but places the focus of rewards on the "smart followers" reputation weight — even if you have dozens of thousands of followers, but your content has no real value, you may still get very few Yap points. This "quality over quantity" evaluation method corrects the drawbacks of purely chasing traffic to some extent, injecting a touch of academic "peer review" into InfoFi information distribution: only content that receives expert endorsements can stand out.
Of course, the specific algorithm details of the Smart Followers system are kept confidential by the official, and we can only infer its general logic from the results. Kaito's team is worried that if the rules are fully transparent, some people might take advantage of the situation to game the system, disrupting the ecological fairness. Currently, the introduction of the social graph has indeed increased the difficulty of the algorithm to resist cheating, but it also poses new challenges for newcomers: how to win the attention and interaction of industry elites has become the key threshold for obtaining high points. On one hand, this is a positive incentive for content creators, but on the other hand, there is a subtle concern that it may evolve into a game controlled by a few elites — after all, even the most intelligent algorithm ultimately assigns value through interpersonal networks.
Technical Costs and Trade-offs in Multi-layer AI Architecture
Having introduced so many "black tech" features, it is also necessary to calmly examine the reality of the cost ledger — supporting Kaito's complex system involves significant technical expenses. First, the cost of data acquisition. As mentioned earlier, obtaining large amounts of Twitter data through regular channels is costly, sometimes tens of thousands of dollars per month. According to industry reports, Kaito initially tried to obtain data through third-party channels or non-public interfaces, but with Twitter tightening policies, these gray methods became unsustainable, forcing Kaito to honestly pay for higher-level API permissions. This directly compelled Kaito to make trade-offs in product strategies: if they continue to provide extensive query access to ordinary users, the monthly API call limit will quickly reach the ceiling.
Kaito currently offers relatively limited free query services to ordinary users, preferring to sell deep data analysis capabilities to institutions and professional clients. For example, some hedge funds subscribe to the Kaito Pro professional version, with monthly fees exceeding $800. By serving a few paying "big clients" to bear the high data bill, this explains Kaito's current choice of a To B (business-to-business) commercial model.
Another major expense is AI computing power. Kaito officially claims to use GPT-4-level AI to understand content, but each call to the ChatGPT-4 interface is essentially "burning money." If they really analyzed each tweet in real-time using GPT-4, the cost would be astronomical. Rough estimation: even using the cheaper ChatGPT-3.5, processing 50,000 tweets could cost thousands of dollars; if using the GPT-4 model, which is several times more expensive, the monthly cost could reach tens of thousands of dollars.
Evidently, Kaito will not do this recklessly. According to speculation, the team may have developed a "reasonable AI labor utilization" strategy: using large models only when necessary, and using rules filtering or small models for predictions in less important areas, trying to minimize the frequency of ChatGPT calls. There are also signs that Kaito is developing its own large models or multi-agent systems, attempting to let some fine-tuned open-source models handle basic semantic scoring tasks. In this way, only complex problems or those requiring long summaries will trigger expensive GPT-4 calls, greatly reducing the average call cost.
Kaito founder Yu Hu revealed that they currently use an AutoGPT heterogeneous agent architecture, deploying multiple ChatGPT models on the backend to work together, with ChatGPT-4 as the underlying core model, while also fine-tuning their own models to reduce reliance on third parties. This multi-layer model architecture reflects Kaito's difficult balance between effectiveness and cost: on one hand, they need to ensure the algorithm analysis is sufficiently excellent and reliable, and on the other hand, they need to carefully manage expenses. This "two-sided dilemma" is an unavoidable operational challenge for the current InfoFi business model. It can be said that Kaito is conducting a "technological gamble" — burning money to build a technological moat on one side, while hoping to find more economically viable alternatives in the future.
Conclusion: Reflections and Future of the InfoFi Model
Kaito's platform design is a bold integration of cutting-edge technology and business models: it quantifies social content into "attention assets," and guides the creation of high-quality information through token incentives. It sounds beautiful, but implementing it is not a smooth road. Kaito's so-called "InfoFi" is, in a way, a new name for SocialFi — whether called Yap points or other names, the essence is still playing a game of traffic and influence monetization through social networks. This is similar to early SocialFi projects like Friend.tech and Stars Arena.
The difference is that Kaito adds a layer of AI filtering and reputation weighting, trying to raise the "quality threshold" of the game, preventing pure botting traffic from running rampant. However, according to the current results, this system still struggles with the Matthew effect: big figures occupy the rankings, high scores and top influence are highly aligned, and small accounts need to rely on the support of big accounts to rise. Is this breaking information monopoly or reinforcing existing circles? This will be one of the core issues that Kaito needs to face in the future.
A more practical challenge lies in the sustainability of the model. Kaito is currently highly dependent on the Twitter ecosystem — whether data sources or user interactions are almost all tied to the X platform. How far can this dependent development model go? If Twitter again increases API prices or tightens data access, can Kaito still function? The current high API fees have already forced Kaito to turn to serving paying customers to support operations. But if the InfoFi model is to expand to mass participation, this cost will eventually need to be balanced.
On the other hand, the token economy supporting Yap incentives also has uncertainties. Currently, the value of Yap points is more in the expectation stage; once market enthusiasm declines and expected value drops, will the top KOLs on the platform switch to other platforms, causing Kaito to face the risk of content loss? KOLs who roam across various platforms tend to go where the returns are higher. If Kaito cannot continuously provide sufficient returns or influence rewards, it will be difficult to retain these top users with sentiment alone.
In summary, for the InfoFi model to be viable, it ultimately needs to achieve a better balance between incentivizing high-quality content creation and maintaining its own ability to generate revenue. Can Kaito find a sustainable development path amidst fierce competition and resource constraints? We will watch and see.
Disclaimer: Contains third-party opinions, does not constitute financial advice




AI Practical Guide
This column focuses on the real progress of Agents: technological evolution, application implementat
Crypto Weekly
Tracking on-chain movements of the smart money and institutions
Frontier Insights
Spotlight on Frontier, trending projects, and breaking events
Blowup Alert
As the 2026 crypto bear market deepens, exit scams and project blowups are becoming increasingly fre
Regulatory Watch
American Crypto Act – timely interpretations of policies worldwide
Popular Airdrop Tutorial
Selected potential airdrop opportunities to gain big with small investments
FusnChain
FusnChain