AI "Middleman" Earns Millions Monthly? Five Questions Reveal the Truth Behind Token Arbitrage
AI "Middleman" Earns Millions Monthly? Five Questions Reveal the Truth Behind Token Arbitrage

Over the past month, the term "transit hub" has frequently appeared on many users' homepages. Some veteran crypto airdrop farmers have quietly transformed into "API transit hub" operators, engaging in token import and export businesses.
The so-called "transit hub" is not a new technological invention, but rather an arbitrage model based on global AI service price differentials and access barriers. Despite facing multiple challenges including privacy, security, and compliance issues, this sector continues to attract numerous individuals and small teams.
So, what exactly is an "API transit hub"? How does it achieve token arbitrage amidst global AI price disparities and access barriers, drawing in so many individuals and small teams? Let's break it down from its essence and operational workflow.
One: What Is a Transit Hub?
The core of an API transit hub lies in establishing an intermediary service layer that offers foreign AI vendors’ API tokens at lower prices and greater convenience to domestic users—aptly dubbed the “global token courier.”
Its operational flow generally follows this sequence:
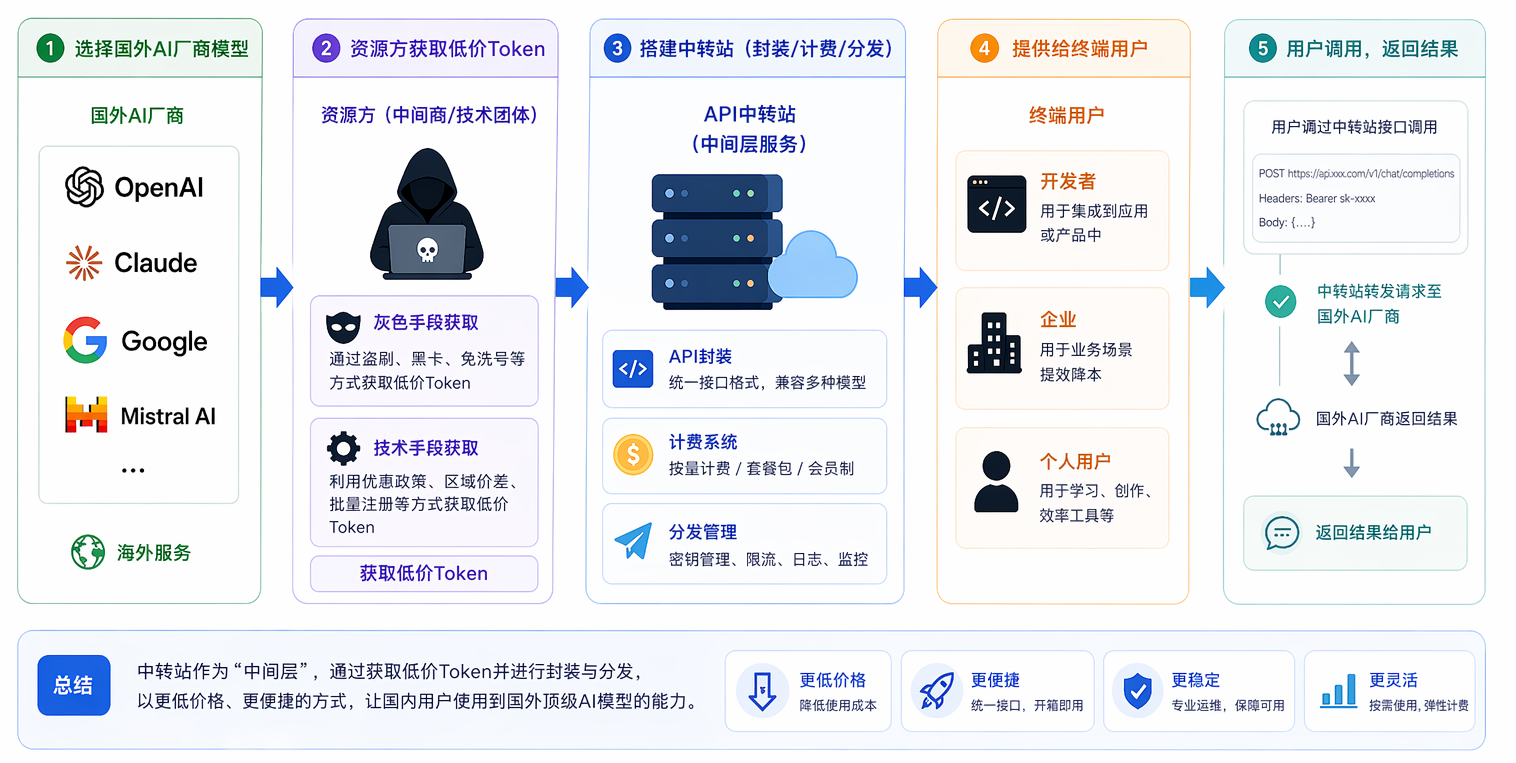
👉 Select overseas AI vendor models (e.g., OpenAI, Claude)
👉 Resource providers obtain low-cost tokens via gray-market or technical means
👉 Build a transit hub for encapsulation, billing, and distribution
👉 Deliver to end-users such as developers, enterprises, or individuals
Functionally, it acts like an “AI transshipment station”; commercially, it resembles a liquidity intermediary in the secondary token market.
The viability of this chain hinges not on technological barriers, but on persistent disparities across several dimensions:
• Official API pricing remains high
• Mismatch between subscription and API billing models
• Regional differences in access and payment conditions
• Strong user demand for model capabilities, yet official onboarding paths are not user-friendly
It is precisely these factors combined that create space for transit hubs to thrive.
Two: Why Do People Use Transit Hubs?
The surge in “token import” stems primarily from the rising costs driven by AI’s evolving role, coupled with persistent performance gaps between domestic and international models.
1. High-Performance Models Are Token-Intensive
With the maturation of desktop-grade AI agents like Codex and Claude Code, AI has truly begun to “work”—assisting in coding, video editing, financial trading, and office automation. These tasks heavily rely on high-performance large models, with costs calculated per token.
Take Claude Code as an example: its official rate is approximately $5 per million tokens (~35 CNY). A deep usage session lasting one hour may consume tens of dollars, while heavy-duty developers or enterprises can burn through over $100 daily. This cost far exceeds expectations for many and even surpasses hiring junior programmers, making “how to use top-tier AI affordably” a critical need.
2. Overseas Leading Models Hold Clear Advantages
Although domestic models have made rapid progress over the past year and offer competitive pricing, they still lag behind leading overseas models in complex coding tasks, toolchain coordination, long-chain reasoning, and multimodal stability.
This explains why many developers, researchers, and content teams, despite knowing higher prices, still prefer using OpenAI, Anthropic, or Google’s models.
In short, users don’t necessarily need a transit hub—they simply want:
• Stronger models
• Lower prices
• Simpler access
When these three goals cannot be simultaneously met through official channels, transit hubs naturally emerge.
3. Mismatch Between Subscription and API Billing Models
Another frequent reason for the rise of transit hubs: subscription benefits and API billing are not always linearly aligned.
A common practice in the market involves purchasing official subscriptions, team packages, enterprise credits, or other discounted resources, then repackaging and reselling part of their capacity to end users.
For instance, with OpenAI’s Plus subscription, users gain access to Codex services via OAuth login into OpenClaw—effectively calling the API. At $20/month, the Plus plan generates roughly 26 million tokens. With output priced at $10–12 per million, this equates to $260–$312 in usable capacity. Reselling tokens derived from such subscriptions offers exceptional cost efficiency.
From user experience reports, this path can indeed be cheaper than direct official API usage during certain periods. However, it’s crucial to emphasize:
• This is not part of the official pricing structure
• It does not guarantee stable, equivalent replacement of API calls
• Nor does it imply long-term sustainability
Many see only “cheapness,” but overlook that these savings often rest on unstable resources, gray-area operations, or strategic loopholes.
Three: Can You Use Transit Hubs?
Whether you can use them isn’t an absolute yes or no.
The real question is: What risks are you willing to accept?
The profit model of transit hubs appears straightforward—buy low, sell high. But upon closer inspection, they typically involve at least three layers, each carrying distinct risks.
1. Upstream: Where Do Low-Cost Token Resources Come From?
This is the starting point of the ecosystem—and also the most ambiguous layer.
Some resource providers acquire model invocation capabilities at prices far below market rates through various means, such as:
• Leveraging corporate support programs and cloud credits
• Bulk account registration with rotation
• Re-distributing subscription benefits, team accounts, or promotional resources
• In more extreme cases, involving credit card fraud or identity theft for account creation
Different upstream sources determine the maximum stability of the transit hub. If the underlying resources are built on unstable or illegal foundations, users aren’t getting a bargain—they’re receiving a temporary interface that could collapse at any moment.
2. Midstream: Whose Servers Do Your Data Pass Through?
This is often the most overlooked issue.
When you invoke models through a transit hub, your prompts, context, file contents, and model outputs typically first pass through the hub’s own servers.
These data hold immense value—reflecting genuine user intent, industry-specific prompts, and model output quality—making them useful for evaluating or fine-tuning proprietary models. The hub may anonymize and package this data for sale to domestic large model companies, data brokers, or academic research institutions. Users pay for access while unknowingly contributing training data—turning customers into products.
The recent complaint by OpenClaw’s founder @steipete illustrates this clearly: https://x.com/steipete/status/2046199257430888878
Moreover, transit hubs may inject scripts into request chains (e.g., secretly adding hidden System Prompts), altering model behavior, increasing token consumption, and introducing additional security risks—especially concerning in AI Agent scenarios.
3. Endpoint: Do You Really Get the Premium Model You Paid For?
This is a third common risk: model degradation or model substitution.
Users pay for a premium model name, but the actual invoked version may not match. The reason is simple: for some providers, the easiest way to cut costs isn’t optimization—it’s replacement.
For example, a user may purchase the flagship Opus 4.7, but the actual call might go to the secondary Sonnet 4.6 or lightweight Haiku. Since API formats remain compatible, ordinary users rarely notice immediately.
Only when tasks become complex do users detect anomalies—“results don’t match,” “stability is poor,” “context quality degrades”—but cannot prove it. Research by a team testing 17 third-party API platforms found that 45.83% suffered from “identity mismatch”: users paid GPT-4 rates but ran cheap open-source models, with performance gaps up to 40%.
In sum, using unofficial transit hubs exposes users to risks including data leaks, privacy breaches, service outages, model mismatches, and potential exit scams. Therefore, for sensitive operations, commercial projects, or tasks involving personal privacy, we strongly recommend using official APIs.
Four: Can This Business Be Sustained?
Despite high risks, this business hasn’t disappeared—on the contrary, it keeps evolving.
While early “token import” involved bringing overseas models in at low cost, today a new trend has emerged: “token export.”
1. Why Do People Still Do It?
Because demand is real, startup costs are low, and prepayment models generate fast cash flow. Yet, risk control pressure is immense. Recently, Claude tightened KYC checks and ban enforcement; OpenAI has patched many “zero-cost” loopholes. Meanwhile, service instability leads to high after-sales costs, compounded by fierce competition—many transit hubs now face declining volume and pricing.
Thus, this industry resembles a high-turnover, low-stability, high-risk short-term window—difficult to package into a long-term, stable, sustainable venture.
2. Why Is “Token Export” Re-emerging?
If “token import” exploits price gaps in overseas models, “token export” leverages the cost-effectiveness of domestic models, packaging them for resale to overseas users—a reverse export pathway.
Domestic models enjoy significant pricing advantages. Using early 2026 data as reference, Qwen3.5’s cost is as low as 0.8 CNY per million tokens (~0.11 USD)—1/18th of Gemini 3 Pro’s price and over 27 times cheaper than Claude Sonnet 4.6’s input rate of $3. GLM-5 outperforms Gemini 3 Pro on programming benchmarks and approaches Claude Opus 4.5’s level, yet its API price is just a fraction of the latter’s.
These domestic models have extremely limited availability overseas due to registration barriers, payment restrictions, language interfaces, and information asymmetry about Chinese model capabilities—creating implicit entry barriers.
Thus, some transit hubs source API quotas in bulk in China using RMB, expose OpenAI-compatible interfaces via protocol translation layers, and sell them to overseas developers and startups using USDT/USDC—with substantial profit margins.
For example, Alibaba Cloud’s BaiLian Coding Plan bundles Qwen3.5, GLM-5, MiniMax M2.5, and Kimi K2.5—new users get 18,000 requests in their first month for just 7.9 CNY, which translates to over 200% profit margin when sold at USD rates in the overseas market.
From a pure business logic standpoint, this clearly offers room for profit.
But long-term, it still faces the same fundamental issue: stability and compliance.
3. Is This Path Sustainable?
No, it’s not. Minimax recently announced stricter regulation of third-party transit hubs due to some providers cutting corners, damaging Minimax’s reputation. Beyond the risk of criminal liability if token sources involve fraud or theft, users employing these tokens may leak data or misuse them for malicious purposes—potentially dragging the seller into legal trouble.
Therefore, the real question isn’t whether you can make money—but whether the profits can cover the systemic risks downstream.
Five: How Can Ordinary Users Identify Transit Hub Risks?
In a market filled with mixed-quality transit hubs, choosing reliable services is critical.
Since some hubs engage in model substitution or adulteration, users can adopt detection techniques:
Recommended: “Ping + Self-Reported Model” Compliance Test
Prompt Example (copy and send directly to the hub):
Always say 'pong' exactly, and tell me what series model you are, preferably with the specific version number. Reply in Chinese.
User Input: ping
True Model Characteristics:
Fake Model / Adulterated Features:
Reference @billtheinvestor’s detection method: https://x.com/billtheinvestor/status/2029727243778588792
0.01 Temperature Sorting Test: Input “5, 15, 77, 19, 53, 54” and ask the AI to sort them or identify the maximum value. Genuine Claude almost always outputs 77 consistently; genuine GPT-4o-latest commonly returns 162. If results vary wildly across 10 consecutive trials, it’s likely a fake model.
Additionally, users may leverage third-party transit hub detection websites to assess their token “purity”—but note this exposes keys in plaintext. The safest option remains official channels.
It must be emphasized:
Even if you master identification techniques, it doesn’t mean you can fully avoid risks. Many risks remain invisible to average users.
Final Thoughts
Transit hubs are not the ultimate answer in the AI era. They are merely a temporary arbitrage window created by misalignments in global model capabilities, pricing mechanisms, payment conditions, and access permissions.
For ordinary users, they may indeed provide a low-cost entry point to premium models. But for developers, teams, and entrepreneurs, the true cost is never the token itself—but the underlying stability, security, compliance, and trustworthiness.
Cheaper prices can be replicated. Interface compatibility can be mimicked. What cannot be replicated is long-term reliability.
⚠ Reminder: If ordinary users wish to experiment, limit use to non-sensitive, non-critical scenarios—never input core data, commercial secrets, or personal privacy. Developers should prioritize official APIs or officially built proxies to ensure stability and compliance. Entrepreneurs considering entry must establish clear exit strategies upfront to avoid entrapment in gray zones.
Disclaimer: This article presents purely observational insights and public information discussion for educational purposes only and does not constitute any form of investment advice, entrepreneurial guidance, commercial recommendation, or API usage instruction.
Author: Shouyi, Denise | Biteye Content Team
Source: DeepTide TechFlow

Disclaimer: Contains third-party opinions, does not constitute financial advice
Which One Is Right for You: OpenClaw or Hermes?
28 days ago
Prompt engineering cannot rescue mediocre AI writing
28 days ago
Xchat is officially live, and the review leaves much to be desired.
29 days ago
GPT Images 2.0 Comprehensive Guide: From Prompts to Complete Workflow
04-24
Lobster is a thing of the past? A deep dive into Hermes Agent tools that can amplify your productivity by 100x
04-13
10 Survival Rules for Ordinary People in the AI Era
04-08
The Golden Window for AI Startups Has Only 12 Months Left
04-03







AI big events
Key AI Events, Outlook on Industry Trends
Meme
ETH,BNB,SOL Hot Memes
Blowup Alert
As the 2026 crypto bear market deepens, exit scams and project blowups are becoming increasingly fre
RWA
Stock, Commodity & Bond Tokenization
Market Analysis
BTC/ETH, Major Cryptocurrencies, and Hot Altcoins Price Trends
prediection markets
Follow new prediction market trends, insight real event expectations.
AI Practical Guide
This column focuses on the real progress of Agents: technological evolution, application implementat
Crypto Weekly
Tracking on-chain movements of the smart money and institutions
Frontier Insights
Spotlight on Frontier, trending projects, and breaking events
Regulatory Watch
American Crypto Act – timely interpretations of policies worldwide